





By Mahavir Bhattacharya
Welcome to the second a part of this two-part weblog collection on the bias-variance tradeoff and its software to buying and selling in monetary markets. Within the first half, we tried to develop an instinct for bias-variance decomposition. On this half, we’ll lengthen what we realized and develop a buying and selling technique.
Conditions
A reader with some primary data of Python and ML ought to have the ability to learn and comprehend the article. These are some pre-requisites:
Half 1 of this weblog collection on the bias-variance tradeoff and its software to buying and selling in monetary markets Linear algebra (primary to intermediate)Python programming (primary to intermediate)Machine studying (working data of regression and regressor fashions)Time collection evaluation (primary to intermediate)Expertise in working with market information and creating, backtesting, and evaluating buying and selling methods
Additionally, I’ve added some hyperlinks for additional studying at related locations all through the weblog.
For those who’re new to Python or want a refresher on it, you can begin with Fundamentals of Python Programming after which transfer to Python for Buying and selling: Primary on Quantra for trading-specific purposes.
To familiarise your self with machine studying, and with the idea of linear regression, you’ll be able to undergo Machine Studying for Buying and selling and Predicting Inventory Costs Utilizing Regression.
As a result of the article additionally covers time collection transformations and stationarity, you’ll be able to familiarise your self with Time Collection Evaluation. Information of dealing with monetary market information and sensible expertise in technique creation, backtesting, and analysis will show you how to apply the article’s learnings to your methods.
On this weblog, we’ll cowl the whole pipeline for utilizing machine studying to construct and backtest a buying and selling technique whereas utilising the bias-variance decomposition to pick the suitable prediction mannequin. So, right here it goes…
The circulation of this text is as follows:
As a ritual, step one is to import the required libraries.
Importing Libraries
I’ve imported the required libraries for all subsequent codes right here. For those who don’t have any of those put in, a ‘pip set up’ command ought to do the trick (in case you don’t need to go away the Jupyter Pocket book atmosphere or work on Google Colab).
Downloading Information
Subsequent, we outline a perform for downloading the information. We’ll use the yfinance API right here.
Discover the argument ‘multi_level_index’. Lately (I’m penning this in April 2025), there have been some modifications within the yfinance API. When downloading value degree and quantity information for any safety by the required API, the ticker title of the safety will get added as a heading.
It seems like this when downloaded:
For individuals (like me!) who’re accustomed to not seeing this additional degree of heading, eradicating it whereas downloading the information is a good suggestion. So we set the ‘multi_level_index’ argument to ‘False’.
Defining Technical Indicators as Predictor Variables
Subsequent, since we’re utilizing machine studying to construct a buying and selling technique, we should embody some options (typically referred to as predictor variables) on which we prepare the machine studying mannequin. Utilizing technical indicators as predictor variables is a good suggestion when buying and selling within the monetary markets. Let’s do it now.
Ultimately, we’ll see the checklist of indicators after we name this perform on the asset dataframe.
Defining the Goal Variable
The subsequent chronological step is to outline the goal variable/s. In our case, we’ll outline a single goal variable, the close-to-close 5-day p.c return. Let’s see what this implies. Suppose as we speak is a Monday, and there aren’t any market holidays, barring the weekends, this week. Think about the p.c change in tomorrow’s (Tuesday’s) closing value over as we speak’s closing value, which might be a close-to-close 1-day p.c return. At Wednesday’s shut, it will be the 2-day p.c return, and so forth, until the next Monday, when it will be the 5-day p.c return. Right here’s the Python implementation for a similar:
Why can we use the shift(-5) right here? Suppose the 5-day p.c return based mostly on the closing value of the next Monday over as we speak’s closing value is 1.2%. Through the use of shift(-5), we’re inserting this worth of 1.2% within the row for as we speak’s OHLC value ranges, quantity, and different technical indicators. Thus, after we feed the information to the ML mannequin for coaching, it learns by contemplating the technical indicators as predictors and the worth of 1.2% in the identical row because the goal variable.
Stroll Ahead Optimisation with PCA and VIF
One important consideration whereas coaching ML fashions is to make sure that they show strong generalisation. Which means that the mannequin ought to have the ability to extrapolate its efficiency on the coaching dataset (typically referred to as in-sample information) to the check dataset (typically referred to as out-of-sample information), and its good (or in any other case) efficiency needs to be attributed primarily to the inherent nature of the information and the mannequin quite than probability.
One strategy in direction of that is combinatorial purged cross-validation with embargoing. You’ll be able to learn this to study extra.
One other strategy is walk-forward optimisation, which we are going to use (learn extra: 1 2).
One other important consideration whereas constructing an ML pipeline is function extraction. In our case, the entire predictors we now have is 21. We have to extract crucial ones from these, and for this, we are going to use Principal Element Evaluation and the Variance Inflation Issue. The previous extracts the highest 4 (a price that I selected to work with; you’ll be able to change it and see how the backtest modifications) combos of options that specify probably the most variance inside the dataset, whereas the latter addresses mutual info, often known as multicollinearity.
Right here’s the Python implementation of constructing a perform that does the above:
Buying and selling Technique Formulation, Backtesting, and Analysis
We now come to the meaty half: the technique formulation. Listed here are the technique outlines:
Preliminary capital: ₹10,000.
Capital to be deployed per commerce: 20% of preliminary capital (₹2,000 in our case).
Lengthy situation: when the 5-day close-to-close p.c return prediction is constructive.
Quick situation: when the 5-day close-to-close p.c return prediction is adverse.
Entry level: open of day (N+1). Thus, if as we speak is a Monday, and the prediction for the 5-day close-to-close p.c returns is constructive as we speak, I’ll go lengthy at Tuesday’s open, else I’ll go brief at Tuesday’s open.
Exit level: shut of day (N+5). Thus, after I get a constructive (adverse) prediction as we speak and go lengthy (brief) throughout Tuesday’s open, I’ll sq. off on the closing value of the next Monday (supplied there aren’t any market holidays in between).
Capital compounding: no. Which means that our earnings (losses) from each commerce should not getting added (subtracted) to (from) the tradable capital, which stays mounted at ₹10,000.
Right here’s the Python code for this technique:
Subsequent, we outline the capabilities to guage the Sharpe ratio and most drawdowns of the technique and a buy-and-hold strategy.
Calling the Capabilities Outlined Beforehand
Now, we start calling among the capabilities talked about above.
We’ll begin with downloading the information utilizing the yfinance API. The ticker and interval are user-driven. When working this code, you’ll be prompted to enter the identical. I selected to work with the 10-year day by day information of the NIFTY-50, the broad market index based mostly on the Nationwide Inventory Trade (NSE) of India. You’ll be able to select a smaller timeframe; the longer the time-frame, the longer it should take for the next codes to run. After downloading the information, we’ll create the technical indicators by calling the ‘create_technical_indicators’ perform we outlined beforehand.
Right here’s the output of the above code:
Enter a sound yfinance API ticker: ^NSEI
Enter the variety of years for downloading information (e.g., 1y, 2y, 5y, 10y): 10y
YF.obtain() has modified argument auto_adjust default to True
[*********************100%***********************] 1 of 1 accomplished
Subsequent, we align the information:
Let’s examine the 2 dataframes ‘indicators’ and ‘data_merged’.
RangeIndex: 2443 entries, 0 to 2442
Information columns (whole 21 columns):
# Column Non-Null Depend Dtype
— —— ————– —–
0 sma_5 2443 non-null float64
1 sma_10 2443 non-null float64
2 ema_5 2443 non-null float64
3 ema_10 2443 non-null float64
4 momentum_5 2443 non-null float64
5 momentum_10 2443 non-null float64
6 roc_5 2443 non-null float64
7 roc_10 2443 non-null float64
8 std_5 2443 non-null float64
9 std_10 2443 non-null float64
10 rsi_14 2443 non-null float64
11 vwap 2443 non-null float64
12 obv 2443 non-null int64
13 adx_14 2443 non-null float64
14 atr_14 2443 non-null float64
15 bollinger_upper 2443 non-null float64
16 bollinger_lower 2443 non-null float64
17 macd 2443 non-null float64
18 cci_20 2443 non-null float64
19 williams_r 2443 non-null float64
20 stochastic_k 2443 non-null float64
dtypes: float64(20), int64(1)
reminiscence utilization: 400.9 KB
Index: 2438 entries, 0 to 2437
Information columns (whole 28 columns):
# Column Non-Null Depend Dtype
— —— ————– —–
0 Date 2438 non-null datetime64[ns]
1 Shut 2438 non-null float64
2 Excessive 2438 non-null float64
3 Low 2438 non-null float64
4 Open 2438 non-null float64
5 Quantity 2438 non-null int64
6 sma_5 2438 non-null float64
7 sma_10 2438 non-null float64
8 ema_5 2438 non-null float64
9 ema_10 2438 non-null float64
10 momentum_5 2438 non-null float64
11 momentum_10 2438 non-null float64
12 roc_5 2438 non-null float64
13 roc_10 2438 non-null float64
14 std_5 2438 non-null float64
15 std_10 2438 non-null float64
16 rsi_14 2438 non-null float64
17 vwap 2438 non-null float64
18 obv 2438 non-null int64
19 adx_14 2438 non-null float64
20 atr_14 2438 non-null float64
21 bollinger_upper 2438 non-null float64
22 bollinger_lower 2438 non-null float64
23 macd 2438 non-null float64
24 cci_20 2438 non-null float64
25 williams_r 2438 non-null float64
26 stochastic_k 2438 non-null float64
27 Goal 2438 non-null float64
dtypes: datetime64[ns](1), float64(25), int64(2)
reminiscence utilization: 552.4 KB
The dataframe ‘indicators’ incorporates all 21 technical indicators talked about earlier.
Bias-Variance Decomposition
Now, the first goal of this weblog is to display how the bias-variance decomposition can help in creating an ML-based buying and selling technique. In fact, we aren’t simply limiting ourselves to it; we’re additionally studying the whole pipeline of making and backtesting an ML-based technique with robustness. However let’s discuss concerning the bias-variance decomposition now.
We start by defining six totally different regression fashions:
You’ll be able to add extra or subtract a pair from the above checklist. The extra regressor fashions there are, the longer the next codes will take to run. Decreasing the variety of estimators within the related fashions can even lead to sooner execution of the next codes.
In case you’re questioning why I selected regressor fashions, it’s as a result of the character of our goal variable is steady, not discrete. Though our buying and selling technique is predicated on the route of the prediction (bullish or bearish), we’re coaching the mannequin to foretell the 5-day return, a steady random variable, quite than the market motion, which is a categorical variable.
After defining the fashions, we outline a perform for the bias-variance decomposition:
You’ll be able to lower the worth of num_rounds to, say, 10, to make the next code run sooner. Nonetheless, a better worth provides a extra strong estimate.
It is a good repository to search for the above code:
https://rasbt.github.io/mlxtend/user_guide/consider/bias_variance_decomp/
Lastly, we run the bias-variance decomposition:
The output of this code is:
Bias-Variance Decomposition for All Fashions:
Complete Error Bias Variance Irreducible Error
LinearRegression 0.000773 0.000749 0.000024 -2.270048e-19
Ridge 0.000763 0.000743 0.000021 1.016440e-19
DecisionTree 0.000953 0.000585 0.000368 -2.710505e-19
Bagging 0.000605 0.000580 0.000025 7.792703e-20
RandomForest 0.000605 0.000580 0.000025 1.287490e-19
GradientBoosting 0.000536 0.000459 0.000077 9.486769e-20
Let’s analyse the above desk. We’ll want to decide on a mannequin that balances bias and variance, which means it neither underfits nor overfits. The choice tree regressor greatest balances bias and variance amongst all six fashions.
Nonetheless, its whole error is the best. Bagging and RandomForest show comparable whole errors. GradientBoosting shows not simply the bottom whole error but additionally a better diploma of variance in comparison with Bagging and RandomForest; thus, its skill to generalise to unseen information needs to be higher than the opposite two, since it will seize extra advanced patterns..
You is likely to be compelled to assume that with such proximity of values, such in-depth evaluation isn’t apt owing to a excessive noise-to-signal ratio. Nonetheless, since we’re working 100 rounds of the bias-variance decomposition, we could be assured within the noise mitigation that outcomes.
Lengthy story lower brief, we’ll select to coach the GradientBoosting regressor, and use it to foretell the goal variable. You’ll be able to, in fact, change the mannequin and see how the technique performs underneath the brand new mannequin. Please word that we’re treating the ML fashions as black bins right here, as exploring their underlying mechanisms is exterior the scope of this weblog. Nonetheless, when utilizing ML fashions for any use case, we should always all the time concentrate on their interior workings and select accordingly.
Having mentioned all of the above, is there a method of lowering the errors of a number of of the above regressor fashions? Sure, and it’s not a method, however an integral a part of working with time collection. Let’s talk about this.
Stationarising the Inputs
We’re working with time collection information (learn extra), and when performing monetary modeling duties, we have to examine for stationarity (learn extra). In our case, we should always examine our enter variables (the predictors) for stationarity. Let’s examine the predictor variables for stationarity and apply differencing to the required predictors (learn extra).
Right here’s the code:
Right here’s a snapshot of the output of the above code:

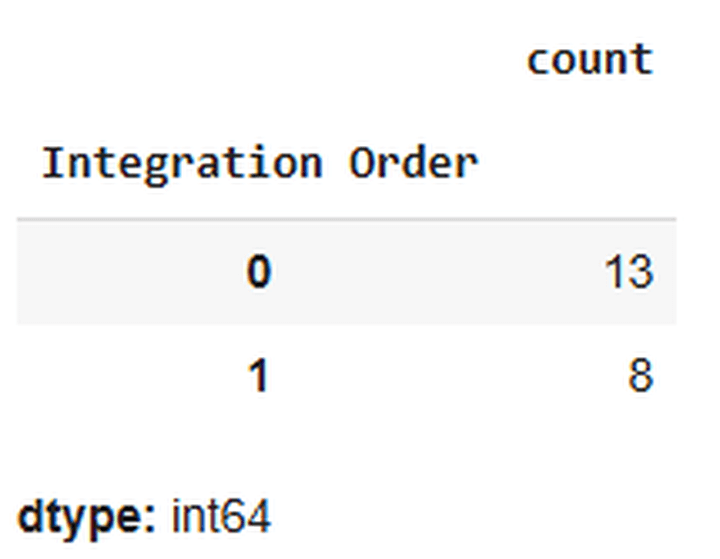
The above output signifies that 13 predictor variables don’t require stationarisation, whereas 8 do. Let’s stationarise them.
Let’s confirm whether or not the stationarising bought carried out as anticipated or not:

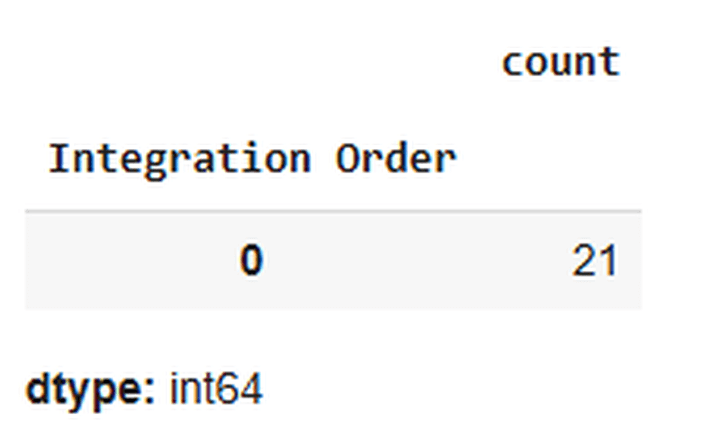
Yup, carried out!
Let’s align the information once more:
Let’s examine the bias-variance decomposition of the fashions with the stationarised predictors:
Right here’s the output:
Bias-Variance Decomposition for All Fashions with Stationarised Predictors:
Complete Error Bias Variance Irreducible Error
LinearRegression 0.000384 0.000369 0.000015 5.421011e-20
Ridge 0.000386 0.000373 0.000013 -3.726945e-20
DecisionTree 0.000888 0.000341 0.000546 2.168404e-19
Bagging 0.000362 0.000338 0.000024 -1.151965e-19
RandomForest 0.000363 0.000338 0.000024 7.453890e-20
GradientBoosting 0.000358 0.000324 0.000034 -3.388132e-20
There you go. Simply by following Time Collection 101, we may cut back the errors of all of the fashions. For a similar cause that we mentioned earlier, we’ll select to run the prediction and backtesting utilizing the GradientBoosting regressor.
Operating a Prediction utilizing the Chosen Mannequin
Subsequent, we run a walk-forward prediction utilizing the chosen mannequin:
Now, we create a dataframe, ‘final_data’, that incorporates solely the open costs, shut costs, precise/realised 5-day returns, and 5-day returns predicted by the mannequin. We’d like the open and shut costs for coming into and exiting trades, and the anticipated 5-day returns, to find out the route during which we take trades. We then name the ‘backtest_strategy’ perform on this dataframe.
Checking the Commerce Logs
The dataframe ‘trades_df_differenced’ incorporates the commerce logs.
We’ll convert the decimals of the values within the dataframe for higher visibility:
Let’s examine the dataframe ‘trades_df_differenced’ now:
Right here’s a snapshot of the output of this code:

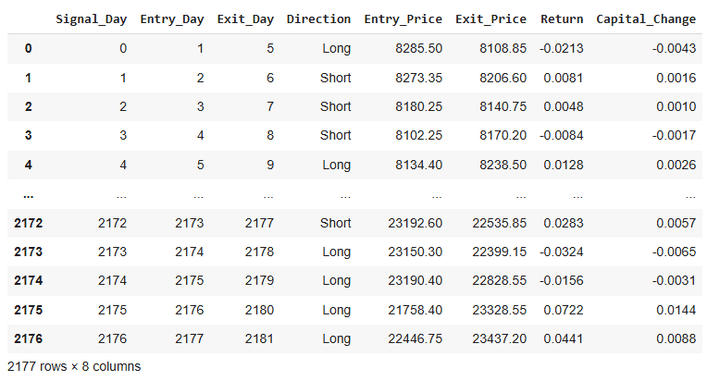
From the desk above, it’s obvious that we take a brand new commerce day by day and deploy 20% of our tradeable capital on every commerce.
Fairness Curves, Sharpe, Drawdown, Hit Ratio, Returns Distribution, Common Returns per Commerce, and CAGR
Let’s calculate the fairness for the technique and the buy-and-hold strategy:
Subsequent, we calculate the Sharpe and the utmost drawdowns:
The above code requires you to enter the risk-free price of your alternative. It’s sometimes the federal government treasury yield. You’ll be able to look it up on-line in your geography. I selected to work with a price of 6.6:
Enter the risk-free price (e.g., for five.3%, enter solely 5.3): 6.6
Now, we’ll reindex the dataframes to a datetime index.
We’ll plot the fairness curves subsequent:
That is how the technique and buy-and-hold fairness curves look when plotted on the identical chart:

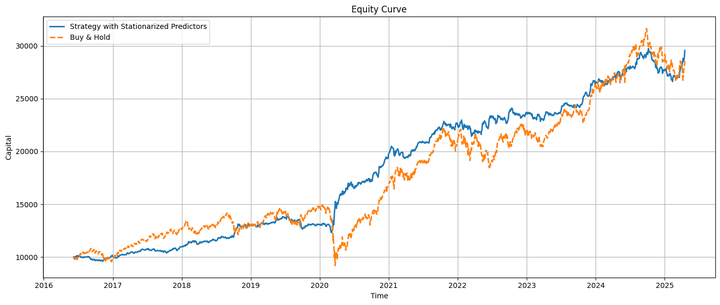
The technique fairness and the underlying transfer nearly in tandem, with the technique underperforming earlier than the COVID-19 pandemic and outperforming afterward. Towards the tip, we’ll talk about some real looking concerns about this relative efficiency.
Let’s take a look on the drawdowns of the technique and the buy-and-hold strategy:

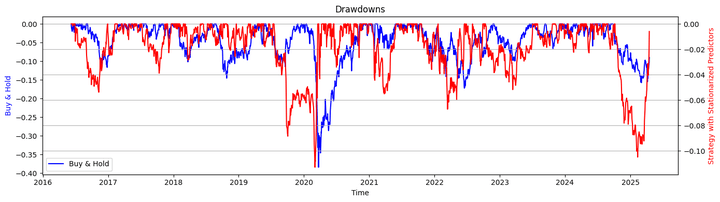
Let’s check out the Sharpe ratios and the utmost drawdown by calling the respective capabilities that we outlined earlier:
Output:
Sharpe Ratio (Technique with Stationarised Predictors): 0.89
Sharpe Ratio (Purchase & Maintain): 0.42
Max Drawdown (Technique with Stationarised Predictors): -11.28%
Max Drawdown (Purchase & Maintain): -38.44%
Right here’s the hit ratio:
Hit Ratio of Technique with Stationarised Predictors: 54.09%
That is how the distribution of the technique returns seems like:

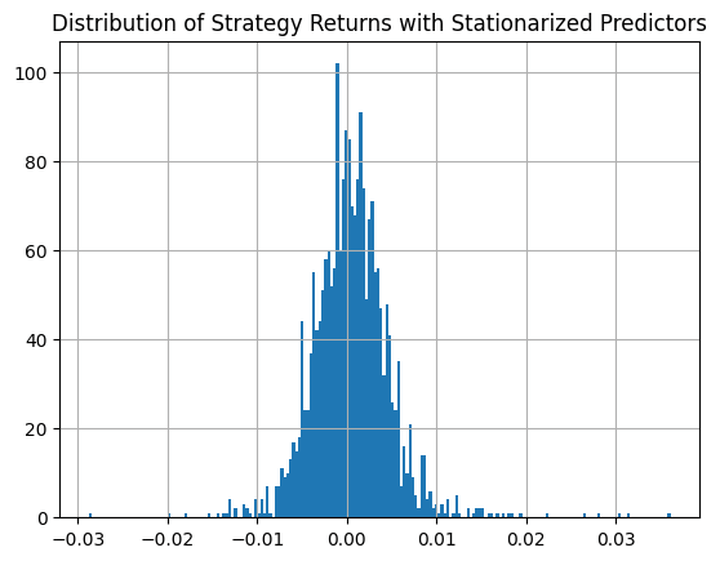
Lastly, let’s calculate the typical earnings (losses) per profitable (dropping) commerce:
Common Revenue for Worthwhile Trades with Stationarised Predictors: 0.0171
Common Loss Loss-Making Trades with Stationarised Predictors: -0.0146
Primarily based on the above commerce metrics, we revenue extra on common in every commerce than we lose. Additionally, the variety of constructive trades exceeds the variety of adverse trades. Due to this fact, our technique is secure on each fronts. The utmost drawdown of the technique is proscribed to 10.48%.
The rationale: The holding interval for any commerce is 5 days, utilizing solely 20% of our obtainable capital per commerce. This additionally reduces the upside potential per commerce. Nonetheless, for the reason that common revenue per worthwhile commerce is increased than the typical loss per loss-making commerce and the variety of worthwhile trades is increased than the variety of loss-making trades, the probabilities of capturing extra upsides are increased than these of capturing extra downsides.
Let’s calculate the compounded annual progress price (CAGR):
CAGR (Purchase & Maintain): 13.0078%
CAGR (Technique with Stationarised Predictors): 13.3382%
Lastly, we’ll consider the regressor mannequin’s accuracy, precision, recall, and f1 scores (learn extra).
Confusion Matrix (Stationarised Predictors):
[[387 508]
[453 834]]
Accuracy (Stationarised Predictors): 0.5596
Recall (Stationarised Predictors): 0.6480
Precision (Stationarised Predictors): 0.6215
F1-Rating (Stationarised Predictors): 0.6345
Some Practical Issues
Our technique outperformed the underlying index in the course of the post-COVID-19 crash interval and marginally outperformed the general market. Nonetheless, if you’re considering of utilizing the skeleton of this technique to generate alphas, you’ll have to peel off some assumptions and take into consideration some real looking concerns:
Transaction Prices: We enter and exit trades day by day, as we noticed earlier. This incurs transaction prices.
Asset Choice: We backtested utilizing the broad market index, which isn’t immediately tradable. We’ll want to decide on ETFs or derivatives with this index because the underlying.
Slippages: We enter our trades on the market’s opening and exit at its shut. Buying and selling exercise could be excessive throughout these intervals, and we could encounter appreciable slippages.
Availability of Partially Tradable Securities: Our backtest implicitly assumes the supply of fractional property. For instance, if our capital is ₹2,000 and the entry value is ₹20,000, we’ll have the ability to purchase or promote 0.1 items of the underlying, ignoring all different prices.
Taxes: Since we’re coming into and exiting trades inside very brief time frames, aside from transaction expenses, we might incur a big quantity of short-term capital features tax (STCG) on the earnings earned. This, in fact, would rely in your native laws.
Threat Administration: Within the backtest, we omitted stop-losses and take-profits. You’re inspired to do this out, see how the technique is modified, and tell us your findings.
Occasion-driven Backtesting: The backtesting we carried out above is vectorised. Nonetheless, in actual life, tomorrow comes solely after as we speak, and we should think about this when performing a backtest. You’ll be able to discover the Blueshift at https://blueshift.quantinsti.com/ and check out backtesting the above technique utilizing an event-driven strategy. An event-driven backtest would additionally account for slippage, transaction prices, implementation shortfalls, and danger administration.
Technique Efficiency: The hit ratio of the technique and the mannequin’s accuracy are roughly 54% and 56%, respectively. These values are marginally higher than these of a coin toss. It is best to do this technique with different asset courses and solely choose these property on which these values are a minimum of 60%. Solely after that ought to you carry out an event-driven backtesting utilizing this technique define.
A Be aware on the Downloadable Python Pocket book
The downloadable pocket book includes backtesting the technique and evaluating its efficiency and the mannequin’s efficiency parameters in a situation the place the predictors should not stationarised and after stationarising them (as we noticed above). Within the former, the technique considerably outperforms the underlying mannequin, and the mannequin shows larger accuracy in its predictions regardless of its increased errors displayed in the course of the bias-variance decomposition. Thus, a well-performing mannequin needn’t essentially translate into a great buying and selling technique, and vice versa.
The Sharpe of the technique with out the predictors stationarised is 2.56, and the CAGR is sort of 27% (versus 0.94 and 14% respectively when the predictors are stationarised). Since we used GradientBoosting, a tree-based mannequin that does not essentially want the predictor variables to be stationarised, we will work with out stationarising the predictors and reap the advantages of the mannequin’s excessive efficiency with non-stationarised predictors.
Be aware that working the pocket book will take a while. Additionally, the performances you receive will differ a bit from what I’ve proven all through the article.
There’s no ‘Good’ in Goodbye…
…but, I’ll must say so now 🙂. Check out the backtest with totally different property by altering among the parameters talked about within the weblog, and tell us your findings. Additionally, as we all the time say, since we aren’t a registered funding advisory, any technique demonstrated as a part of our content material is for demonstrative, academic, and informational functions solely, and shouldn’t be construed as buying and selling or funding recommendation. Nonetheless, in case you’re in a position to incorporate all of the aforementioned real looking elements, extensively backtest and ahead check the technique (with or with out some tweaks), generate vital alpha, and make substantial returns by deploying it within the markets, do share the excellent news with us as a remark beneath. We’ll be joyful in your success 🙂. Till subsequent time…
Credit
Jose Carlos Tanaka and Vivek Krishnamoorthy, thanks in your meticulous suggestions; it helped form this text!Chainika Thakar, thanks for rendering this and making it obtainable to the world!
Subsequent Steps
After going by the above, you’ll be able to comply with a couple of structured studying paths if you wish to broaden and/or deepen your understanding of buying and selling mannequin efficiency, ML technique improvement, and backtesting workflows.
To grasp every element of this technique — from Python and PCA to stationarity and backtesting — discover topic-specific Quantra programs like:
For these aiming to consolidate all of this data right into a structured, mentor-led format, the Govt Programme in Algorithmic Buying and selling (EPAT) affords a great subsequent step. EPAT covers every part from Python and statistics to machine studying, time collection modeling, backtesting, and efficiency metrics analysis — equipping you to construct and deploy strong, data-driven methods at scale.
File within the obtain:
Bias Variance Decomposition – Python pocket book
Be at liberty to make modifications to the code as per your consolation.
Login to Obtain
All investments and buying and selling within the inventory market contain danger. Any choice to position trades within the monetary markets, together with buying and selling in inventory or choices or different monetary devices is a private choice that ought to solely be made after thorough analysis, together with a private danger and monetary evaluation and the engagement {of professional} help to the extent you consider obligatory. The buying and selling methods or associated info talked about on this article is for informational functions solely.




")





