

By Vivek Krishnamoorthy
This publish on Bayesian inference is the second of a multi-part collection on Bayesian statistics and strategies utilized in quantitative finance.
In my earlier publish, I gave a leisurely introduction to Bayesian statistics and whereas doing so distinguished between the frequentist and the Bayesian outlook of the world. I dwelt on how every of their underlying philosophies influenced their evaluation of varied probabilistic phenomena. I then mentioned the Bayes’ Theorem together with some illustrations to assist lay the constructing blocks of Bayesian statistics.
Intent of this Submit
My goal right here is to assist develop a deeper understanding of statistical evaluation by specializing in the methodologies adopted by frequentist statistics and Bayesian statistics. I consciously select to deal with the programming and simulation facets utilizing Python in my subsequent publish.
I now instantiate the beforehand mentioned concepts with a easy coin-tossing instance tailored from “Introduction to Bayesian Econometrics (2nd Version)”.
Instance: A Repeated Coin-Tossing Experiment
Suppose we’re desirous about estimating the bias of a coin whose equity is unknown. We outline θ (the Greek letter ‘theta’) because the likelihood of getting a head after a coin is tossed. θ is the unknown parameter we need to estimate. We intend to take action by inspecting the outcomes of tossing the coin a number of occasions. Allow us to denote y as a realization of the random variable Y (representing the result of a coin toss). Let Y=1 if a coin toss ends in heads and Y=0 if a coin toss ends in tails. Primarily, we’re assigning 1 to heads and 0 to tails.
∴ P(Y=1|θ)=θ ; P(Y=0|θ)=1−θ
Based mostly on our above setup, Y will be modelled as a Bernoulli distribution which we denote as
Y ∼ Bernoulli (θ)
I now briefly view our experimental setup via the lens of the frequentist and the Bayesian earlier than continuing with our estimation of the unknown parameter θ.
Two Views on the Experiment Setup
In classical statistics (i.e. the frequentist method), our parameter θ is a set however unknown worth mendacity between 0 and 1. The information we gather is one realization of a recurrent (i.e. repeating this n-toss experiment say N occasions) experiment. Classical estimation strategies like the strategy of most chance are used to reach at θ̄̂ (referred to as ‘theta hat’), an estimate for the unknown parameter θ. In statistics, we often specific an estimate by placing a hat over the title of the parameter. I dilate this concept within the subsequent part. To restate what has been mentioned beforehand, we observe that within the frequentist universe, the parameter is mounted however the information is various.
Bayesian statistics is basically completely different. Right here, the parameter θ is handled as a random variable since there may be uncertainty about its worth. It, due to this fact, is smart for us to treat our parameter as a random variable which may have an related likelihood distribution. With a purpose to apply Bayesian inference, we flip our consideration to one of many elementary legal guidelines of likelihood idea, Bayes’ Theorem that we had seen beforehand.
I exploit the mathematical type of Bayes’ Theorem as a technique to set up a reference to Bayesian inference.
……..  (1)
(1)
To repeat what I mentioned in my earlier publish, what makes this theorem so useful is it permits us to invert a conditional likelihood. So if we observe a phenomenon and gather information or proof about it, the theory helps us analytically outline the conditional likelihood of various doable causes given the proof.
Let’s now apply this to our instance by utilizing the notations we had outlined earlier. I label A = θ and B = y. Within the discipline of Bayesian statistics, there are particular names used for every of those phrases which I spell out under and use subsequently. (1) will be rewritten as:
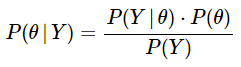 …….. (2)
…….. (2)
the place:
P(θ) is the prior likelihood. We specific our perception concerning the trigger θ BEFORE observing the proof Y. In our instance, the prior can be quantifying our a priori perception on the equity of the coin (right here we will begin with the belief that it’s an unbiased coin, so θ = 1/2). P(Y|θ) is the chance. Right here is the place the actual motion occurs. That is the likelihood of the noticed pattern or proof given the hypothesized trigger. Allow us to, with out lack of generality, assume that we get hold of 5 heads in 8 coin tosses. Presuming the coin to be unbiased as specified above, the chance can be the likelihood of observing 5 heads in 8 tosses on condition that θ = 1/2. P(θ|Y) is the posterior likelihood. That is the likelihood of the underlying trigger θ AFTER observing the proof y. Right here, we compute our up to date or a posteriori perception on the bias of the coin after observing 5 heads in 8 coin tosses utilizing Bayes’ theorem. P(Y) is the likelihood of the info or proof. We typically additionally name this the marginal chance. That is obtained by taking the weighted sum (or integral) of the chance operate of the proof throughout all doable values of θ. In our instance, we might compute the likelihood of 5 heads in 8 coin tosses for all doable beliefs about θ. This time period is used to normalize the posterior likelihood. Since it’s unbiased of the parameter to be estimated θ, it’s mathematically extra tractable to precise the posterior likelihood as:
P(θ|Y) ∝ P(Y|θ) × P(θ) …….(3)
(3) is an important expression in Bayesian statistics and bears repeating. For readability, I paraphrase what I mentioned earlier. Bayesian inference permits us to turnaround conditional chances i.e. use the prior chances and the chance capabilities to supply a connecting hyperlink to the posterior chances i.e. P(θ|Y) granted that we solely know P(Y|θ) and the prior, P(θ). I discover it useful to view (3) as:
Posterior Likelihood ∝ Probability × Prior Likelihood ………. (4)
The experimental goal is to get an estimate of the unknown parameter θ based mostly on the result of n unbiased coin tosses. The coin tosses generate the pattern or information y = (y1, y2, …, yn), the place yi is 1 or 0 based mostly on the results of the ith coin toss.
I now present the frequentist and Bayesian approaches to fulfilling this goal. Be happy to cursorily skim via the derivations I contact upon right here in case you are not within the arithmetic behind it. You’ll be able to nonetheless develop ample intuitions and study to make use of Bayesian strategies in follow.
Estimating θ: The Frequentist Method
We compute the joint likelihood operate utilizing the utmost chance estimation (MLE) method. The likelihood of the result for a single coin toss will be elegantly expressed as:
![]()
For a given worth of θ, the joint likelihood of the result for n unbiased coin tosses is the product of the likelihood of every particular person end result:
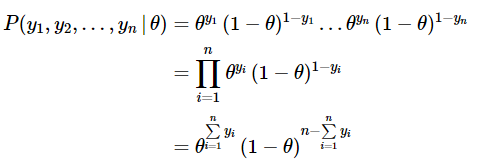 ……. (5)
……. (5)
As we will see in (4), the expression labored out is a operate of the unknown parameter θ given the observations from our experiment. This operate of θ known as the chance operate and is often referred to within the literature as:
![]() ……….. (6)
……….. (6)
OR
![]() …………… (7)
…………… (7)
We wish to compute the worth of θ which is probably to have yielded the noticed set of outcomes. That is referred to as the utmost chance estimate, θ̄̂ (‘theta hat’). For analytically computing it, we trivially take the primary order spinoff of (6) with respect to the parameter and set it equal to zero. It’s prudent to additionally take the second spinoff and examine the signal of its worth at θ = θ̄̂ to make sure that the estimate is certainly the maxima. We regularly typically take the log of the chance operate because it significantly simplifies the dedication of the utmost chance estimator θ̄̂ . It ought to due to this fact not shock you that the literature is replete with log chance capabilities and their options.
Estimating θ: The Bayesian Method
I now change the notations we’ve used to this point to make them a bit extra exact mathematically. I’ll use these notations all through this collection now. The rationale for this alteration is in order that we will suitably ascribe every time period with symbols that remind us of their random nature. There’s uncertainty over the values of θ, Y, and many others., we, due to this fact, regard them as random variables and assign them corresponding likelihood distributions which I do under.
Notations for the Density and Distribution Features
π(⋅) (the Greek letter ‘pi’) to indicate the likelihood distribution operate of the prior (that is pertaining to θ) and π(⋅|y) to indicate the posterior density operate of the parameter we try and estimate.f(⋅) to indicate the likelihood density operate (pdf) for steady random variables and p(.) which is the likelihood mass operate (pmf) of discrete random variables. Nevertheless, for simplicity, I exploit f(⋅) no matter whether or not the random variable Y is steady or discrete.The joint density operate will proceed to be denoted as L(θ|⋅). to indicate the chance operate which is the joint density of the pattern values and is often the product of the pdf’s/pmf’s of the pattern values from our information.
Do not forget that θ is the parameter we try to estimate.
(2) and (3) will be rewritten as
π(θ|y) = [f(y|θ)⋅π(θ)] / f(y) ……(8)
π(θ|y)∝f(y|θ)×π(θ) …………….(9)
Said in phrases, the posterior distribution operate is proportional to the chance operate occasions the prior distribution operate. I redraw your consideration to (4) and current it in congruence with our new notations.
Posterior PDF ∝ Probability × Prior PDF ……….(10)
I now rewrite (8) and (9) utilizing the chance operate L(θ|Y) outlined earlier in (7).
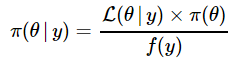 ……… (11)
……… (11)
![]() ………..(12)
………..(12)
The denominator of (11) is the likelihood distribution of the proof or information. I reiterate what I’ve beforehand talked about whereas inspecting (3): A helpful method of contemplating the posterior density is utilizing the proportionality method as seen in (12). That method, we needn’t fear concerning the f(y) time period on the RHS of (11).
For the mathematically curious amongst you, I now take you briefly down a unnecessary rabbit gap to elucidate it incompletely. Maybe, later in our journey, I’ll write a separate publish brooding on these trivialities.
In (11), f(y) is the proportionality fixed that makes the posterior distribution a correct density operate integrating to 1. Once we study it extra intently, we see that’s, in truth, the unconditional (marginal) distribution of the random variable Y. We will decide it analytically by integrating over all doable values of the parameter θ. Since we’re integrating out θ, we discover that f(y) doesn’t rely on θ.
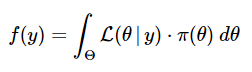
OR
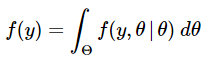
(11) and (12) characterize the continual variations of the Bayes’ Theorem.
The posterior distribution is central to Bayesian statistics and inference as a result of it blends all of the up to date details about the parameter θ in a single expression. This consists of details about θ earlier than the observations had been inspected and that is captured via the prior distribution. The data contained within the observations is captured via the chance operate.
We will regard (11) as a technique of updating data and this concept is additional exemplified by the prior-posterior nomenclature.
The prior distribution of θ, π(θ) represents the data obtainable about its doable values earlier than recording the observations y.The chance operate L(θ|y) of θ is then decided based mostly on the observations y.The posterior distribution of θ, π(θ|y) summarizes all of the obtainable details about the unknown parameter θ after recording and incorporating the observations y.
The Bayesian estimate of θ can be the weighted common of the prior estimate and the utmost chance estimate, θ̄̂ . Because the variety of observations n will increase and approached infinity, the load on the prior estimate approaches zero and the load on the MLE approaches one. This means that the Bayesian and frequentist estimates would converge as our pattern dimension will get bigger.
To make clear, in a classical or frequentist setting, the standard estimator of the parameter, θ is the ML estimator, θ̄̂ . Right here, the prior is implicitly handled as a relentless.
Abstract
I’ve devoted this publish to deriving the elemental results of Bayesian statistics, viz. (10) . The essence of this expression is to characterize uncertainty by combining the information obtained from two sources – observations and prior beliefs. In doing so, I launched the ideas of prior distributions, chance capabilities and posterior distributions in addition to the comparability of the frequentist and Bayesian methodologies. In my subsequent publish, I intend to make good my promise of illustrating the above instance with simulations in Python.
Bayesian statistics is a vital a part of quantitative methods that are a part of an algorithmic dealer’s handbook. The Government Programme in Algorithmic Buying and selling (EPAT™) course by QuantInsti® covers coaching modules like Statistics & Econometrics, Monetary Computing & Know-how, and Algorithmic & Quantitative Buying and selling that equip you with the required talent units for making use of numerous buying and selling devices and platforms to be a profitable dealer.
Disclaimer: All investments and buying and selling within the inventory market contain threat. Any selections to put trades within the monetary markets, together with buying and selling in inventory or choices or different monetary devices is a private resolution that ought to solely be made after thorough analysis, together with a private threat and monetary evaluation and the engagement {of professional} help to the extent you consider vital. The buying and selling methods or associated data talked about on this article is for informational functions solely.



